

 | Rubicon is a modular Swiss Army knife for data management that provides AI/ML-powered tools and integrations to simplify data ingest, storage, and analysis and make all aspects of the data lifecycle transparent and accessible to all. |
Rubicon was purpose built to be deployable anywhere and used by anyone for processing any data, from operators looking for quick answers at the tactical edge on low Size, Weight, and Power (SWAP) hardware to commanders trying to merge information across multiple operations and missions in order to understand the big picture at a strategic level in a multi-tenant cloud environment.
Rubicon was developed, in part, via a Small Business Innovation Research (SBIR) project with US Special Operations Command. SBIRs enable small businesses to work collaboratively with the Government to create, adapt, and develop technologies relevant for the Public Sector use-case.

| 
|
Key Features:
- Built on Open Source: reduces costs and vendor lock-in
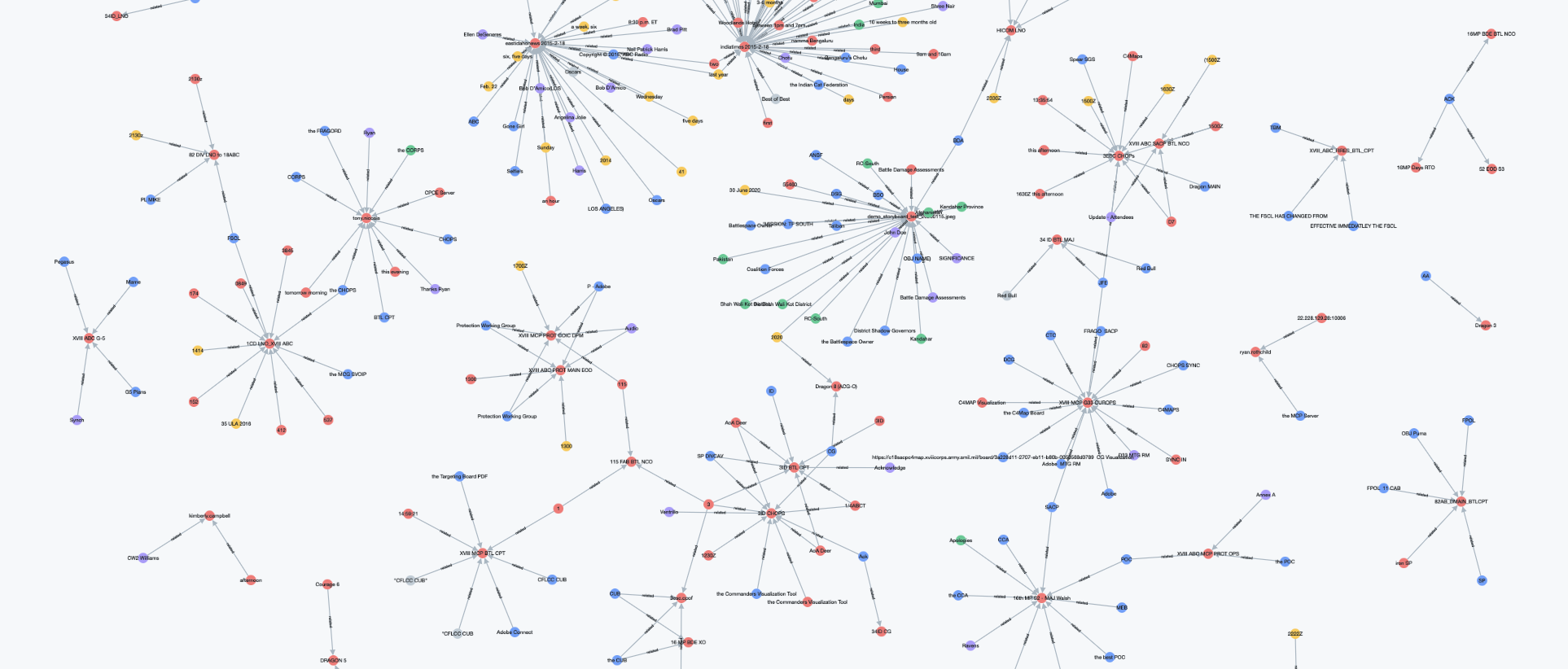
- Modular: built from the ground up as modular building blocks using Docker and based on the microservices concept. Components of the architecture can stand alone or be integrated and orchestrated as needed to fulfill mission requirements.
- Multiple approaches to data storage: effective and efficient data storage and indexing is not a one-size fits all proposition. Rubicon provides an ensemble of storage and indexing approaches that enable and support a variety of analytic use cases: cost-effective, long-term raw data storage in a data lake for recovery and reingest as needed; full-text indices for text based queries; spatio-temporal indices for analyzing data in space and time; and, graph indices for connecting the dots between related entities. This technique combines the strengths of each storage approach to return faster, better, and more complete answers than using a single approach alone.
- Simple data Extract, Transform, and Load (ETL): Rubicon ties ETL to raw data storage, and files are stored in buckets that represent processing status. Data is never lost, and users can immediately grok the processing status of individual datasets and files just by looking at the data lake directories.
- Secure storage and access: record and cell-level security is baked into data storage. Security attributes are stored with records and individual fields, and users and external systems can only see data they are allowed to see based on approved access level.
- A variety of microservice-based analytic tools for enriching and exploiting data: extract text, understand this text using Natural Language Processing (NLP) and detect entities using Named Entity Recognition (NER), detect and extract objects and text in images and video, connect the dots across disparate data, make data searchable and analyzable in a variety of ways. Rubicon provides novel building blocks for common data enrichment and exploitation functions. These blocks can be swapped out with alternatives as a given deployment evolves or as newer, better, faster AI/ML techniques come online.
- Simple, intuitive user interfaces: users should be able to understand what data is available and how the system leverages that data. Analytic capabilities should be explainable, and users should be able to configure, understand and trust the outputs from these analytics. Data and derived information should be organized and easily discoverable and usable by end users.
Related Focus Areas:
Artificial Intelligence and Machine Learning
Data Analytics
Mission Applications